更新时间:2025-11-11 18:12:00 编辑:丁丁小编
来源:点击查看
简介
在这个AI大航海时代,我们似乎每天都在见证新的奇迹,但一个现实却鲜少被提及:全球7000多种语言中,绝大多数在AI的世界里是隐形的。当下的语音识别系统,大多只偏爱那些拥有海量数据的主流语言。

现在,Meta的基础人工智能研究(FAIR)团队决定做点不一样的。他们近日正式推出了Omnilingual ASR,一个雄心勃勃的自动语音识别系统。
它的目标简单粗暴:听懂这个星球上的大多数人。

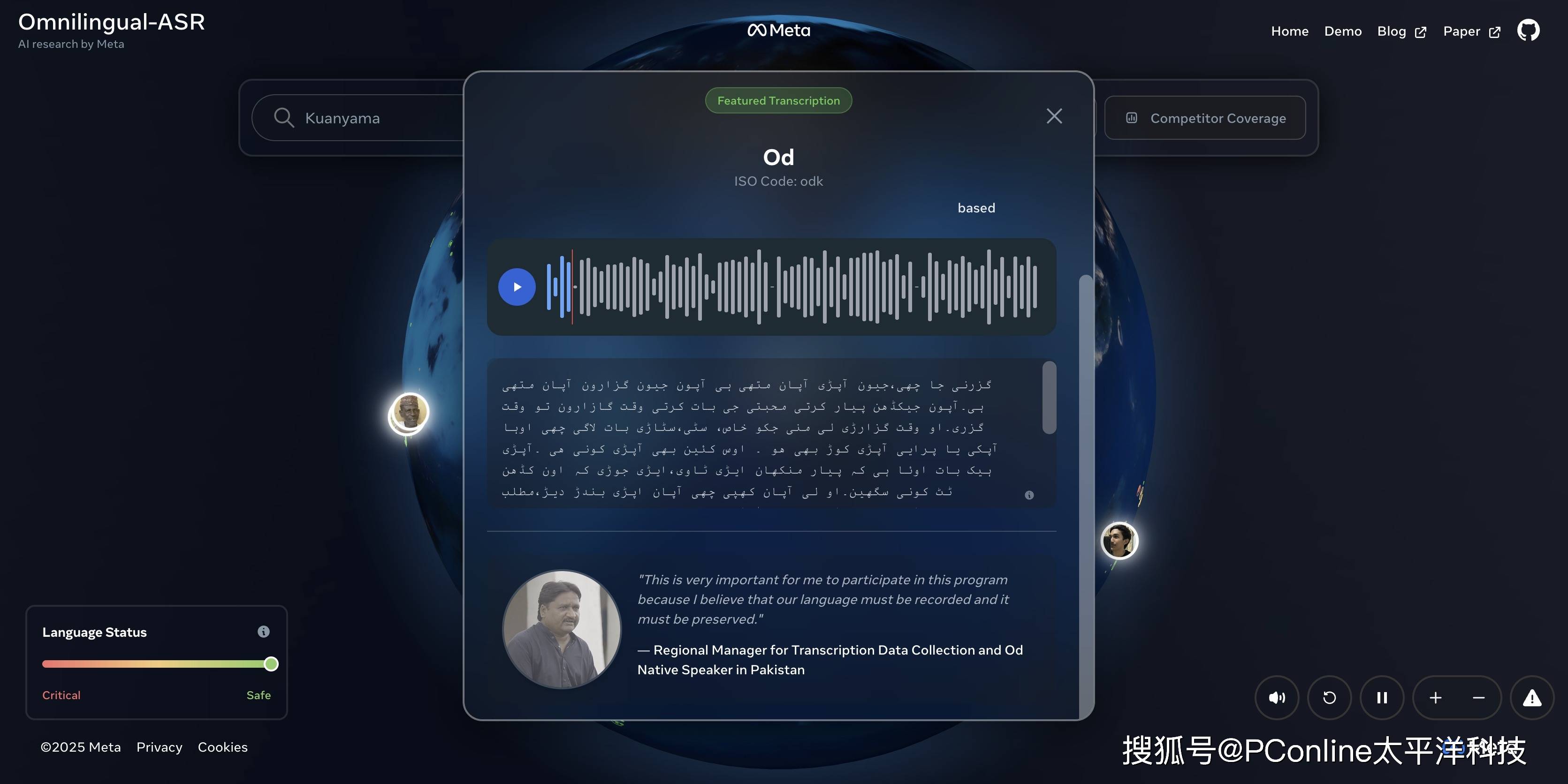
Omnilingual ASR的第一个数字就足够震撼:它能够转录超过1600种口语语言。
让我们花点时间消化一下这个数字。大多数人甚至无法在地图上指出1600种语言的分布地。更关键的是,Meta指出,在这1600种语言中,有整整500种,以前从未被任何人工智能系统覆盖过。
这不仅仅是量变,这是在AI版图上点亮了500个全新的、此前完全黑暗的区域。FAIR团队明确表示,他们的目标是迈向一个真正的“通用转录系统”,弥合现有AI工具在语言覆盖上的巨大鸿沟。
当然,科技圈的看客们都是老江湖了,覆盖面广不代表体验好。如果一个系统能听懂1600种语言,但每种都错得离谱,那也只是个昂贵的玩具。
Omnilingual ASR的性能数据看起来相当扎实:
在它支持的1600种语言中,有高达78%的语言实现了低于10个字符的错误率(CER)。这是一个在实际应用中基本可用的标准。
对于那些资源丰富的语言(拥有至少10小时的训练音频),这个标准(低于10 CER)的覆盖率达到了惊人的95%。
真正的考验在于低资源语言(音频时长不足10小时)。即便如此,Omnilingual ASR依然为其中36%的语言提供了低于10 CER的可用转录,这对于那些几乎被数字世界遗忘的群体来说,意义重大。

Omnilingual ASR的杀手锏,是一种被称为“自带语言”的选项。
这个功能巧妙地借鉴了大型语言模型(LLM)中流行的“情境学习”(In-context Learning)技术。这意味着用户不再需要祈祷Meta的下一次更新能包含自己的母语。
相反,用户只需提供极少量的音频和文本配对样本——比如几分钟的录音和对应的文字——系统就能直接从这些样本中“现场学习”一门新语言。整个过程不需要伤筋动骨的重新训练,也不需要消耗海量的计算资源。
Meta表示,从理论上讲,这种方法有望将Omnilingual ASR的覆盖范围从1600种一举扩展到超过5400种。这几乎是在向全球7000多种语言的终极目标发起了冲锋。

按照FAIR团队的传统,这么好的东西,当然要开源。Meta这次提供了一个完整的“开源生态位”:
模型开源:Omnilingual ASR基于PyTorch的fairseq2框架构建,以Apache 2.0许可证发布。这意味着什么?意味着从研究人员到开发者,甚至商业公司,都可以自由使用、修改和构建自己的应用。模型提供了从3亿参数(适用于低功耗设备)到70亿参数(追求“顶级准确度”)的多种版本,任君选择。
数据集发布:Meta同步推出了“全语言自动语音识别语料库”(Omnilingual ASR Corpus)。这是一个包含了350种代表性不足语言的大型转录语音数据集,以CC-BY(知识共享署名许可)协议发布。
Meta此举,无异于向全球开发者社区发出邀请:工具和数据都在这里了,请尽情发挥,为你们的本地社区构建真正好用的工具。
总而言之,Omnilingual ASR的推出,是打破全球语言壁垒的重要一步。它不仅是技术上的炫技,更是在AI普惠化和全球语言平等方面,投下了一块沉甸甸的压舱石。