
更新时间:2025-09-28 11:02:56 编辑:丁丁小编
来源:点击查看
简介
近日,苹果公司发布了一篇研究论文,揭晓了其在图像处理领域的最新力作:一个名为Manzano的新型图像模型。此举被视为苹果在生成式AI领域追赶并挑战行业巨头OpenAI和谷歌的重要信号。

Manzano的核心突破在于它巧妙地融合了图像理解与图像生成这两项关键能力。当前,许多开源模型往往顾此失彼,难以同时精通这两项任务,而商业闭源系统则普遍具备这种双重能力。苹果的研究表明,Manzano的设计旨在弥合这一差距,使其在处理效率和最终效果上,能够与GPT-4o及谷歌的图像生成技术等顶级商业系统相提并论。

尽管苹果尚未公开发布Manzano,也未提供任何公开演示,但其研究团队分享的论文及附带的低分辨率样本,已经足够展示其强大的潜力。在面对复杂和挑战性的提示时,Manzano的生成结果与GPT-4o及谷歌Nano Banana模型的输出不相上下。

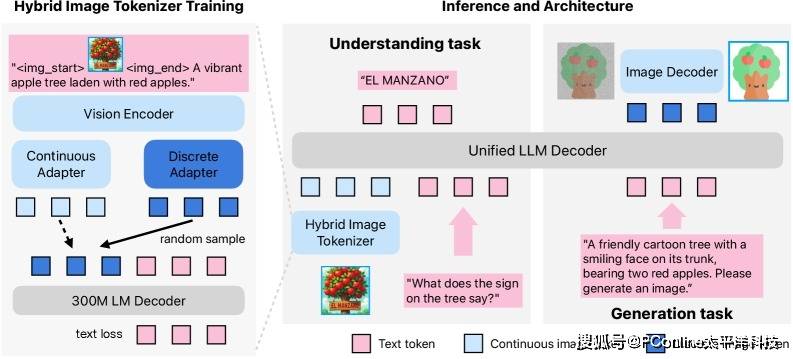
Manzano之所以能实现这一技术飞跃,其关键在于采用了一种创新的混合图像标记器。这一设计理念让模型能够同时输出两种不同类型的标记:用于图像理解的连续标记,它以浮点数形式精确表征图像内容;用于图像生成的离散标记,它将图像内容归纳为固定的类别。由于这两种标记源自同一个编码器,从而有效避免了传统模型中因架构分离而可能产生的内在冲突和信息损失。

在整体架构上,Manzano由三部分构成:混合分词器、一个统一的语言模型以及一个独立的、专用于最终输出的图像解码器。为了适应不同场景的需求,苹果还构建了三种不同参数规模的图像解码器,分别为9000万、1.75亿和3.52亿参数,能够支持从256像素到2048像素不等的图像分辨率。
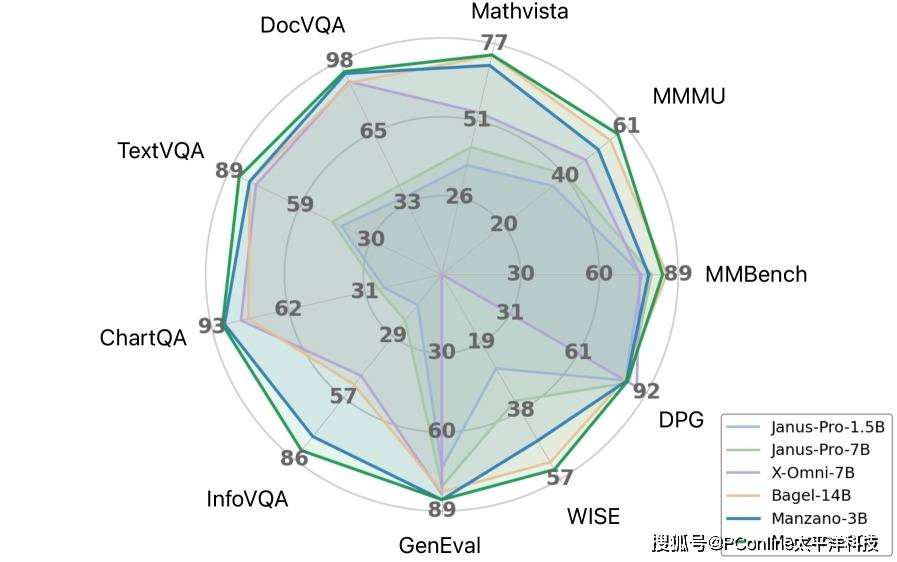
性能测试结果印证了Manzano架构的优越性。在多个行业基准测试中,该模型均表现出色。特别是在处理文本密集型的视觉任务时,其30亿参数版本的模型得分尤为突出。研究同时揭示,随着模型参数量从3亿稳步增加至30亿,其综合性能也呈现出持续且显著的提升。
除了完成传统的图像编辑工作,Manzano还展现了执行更高级任务的能力,包括根据文字提示进行内容编辑、实现艺术风格的迁移、对图像进行智能填充和无缝扩展,甚至还能进行深度估计。
苹果认为,Manzano不仅是现有模型的一个可行替代方案,其模块化的设计思想更有可能对未来多模态人工智能的发展路径产生深远影响,预示着一个更加高效、整合的AI新时代的到来。





