更新时间:2025-04-28 14:03:00 编辑:丁丁小编
来源:点击查看
简介
还记得那个能一口气读完百万字文档的“效率神器”Kimi吗?在DeepSeek R1开源之后,Kimi似乎就有点失宠了,不过这两天它又“杀”回来了。月之暗面团队重磅推出全新音频大模型——Kimi-Audio,训练数据多达1300万小时,一举刷新了12项国际音频处理记录,而且直接开源了!
音频AI里的“六边形战士”
相较于在文本和图像领域取得的显著进展,音频AI因其数据的复杂性、实时性以及对声学环境的敏感性,发展相对面临更多挑战。而Kimi-Audio不仅能将声音转化为文字,更是一个能“听懂”音频内容、理解其中含义、分析情感甚至生成自然语音的全能AI音频模型。
全场景通吃,覆盖音频AI核心任务:Kimi-Audio 的设计目标是成为通用的音频基础模型,能处理多种音频任务,包括语音识别、音频问答、情感识别、声音/场景分类、自动字幕、端到端语音对话等。
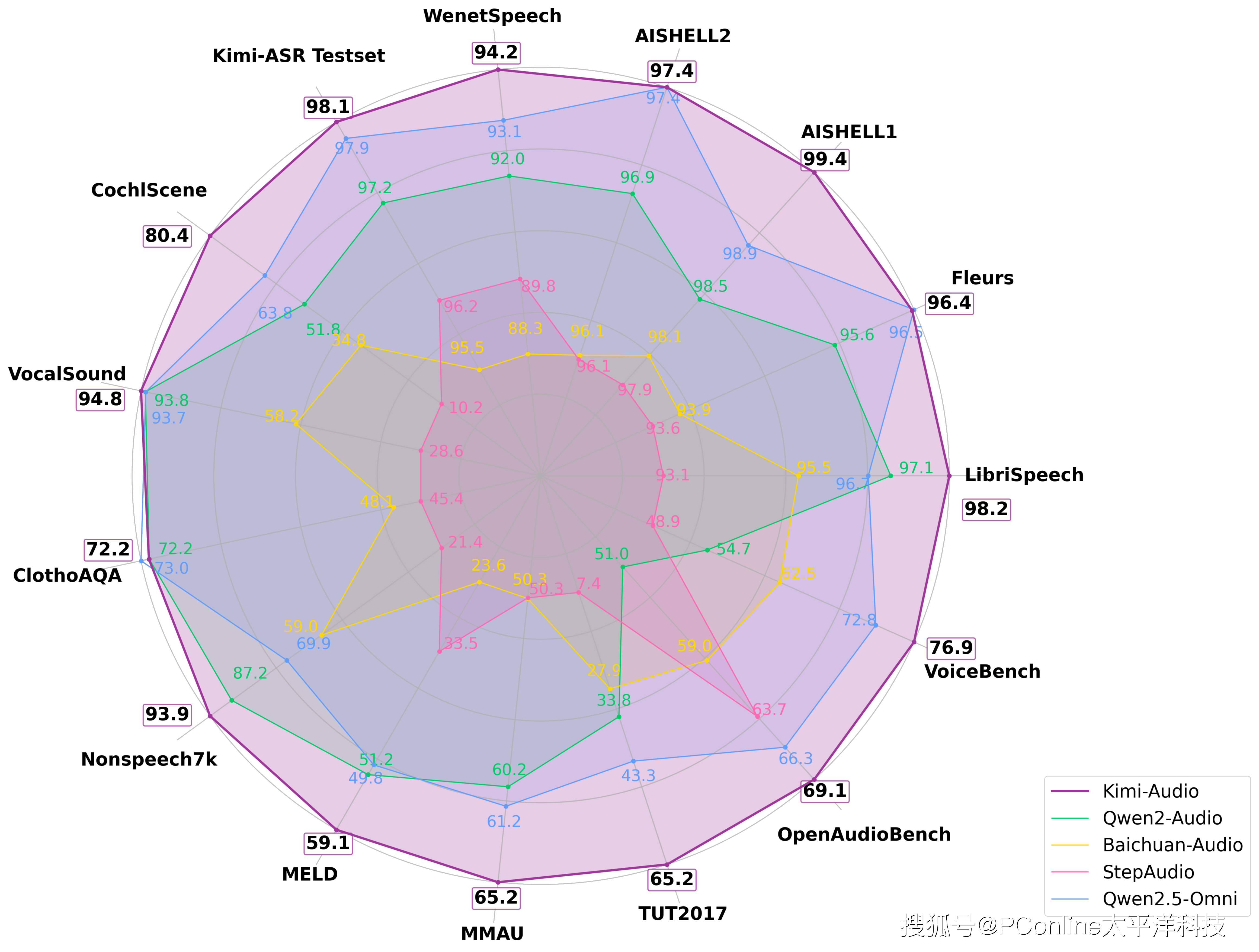
性能碾压,多项权威测试斩获第一:Kimi-Audio 在十多项国际权威测试中表现惊人,均取得领先地位。尤其在语音识别任务中,错误率低至1.28%(比许多同类模型低一半以上),声音分类等任务准确率也接近满分。
开源免费,大家都能用: 与许多闭源商业模型不同,月之暗面选择将Kimi-Audio的核心代码、模型权重以及评测工具等全部开源。这意味着全球的开发者、研究机构和企业都可以免费获取Kimi-Audio的技术,并在其基础上进行二次开发、定制和创新,以适应方言、特定行业术语或小众声音场景。
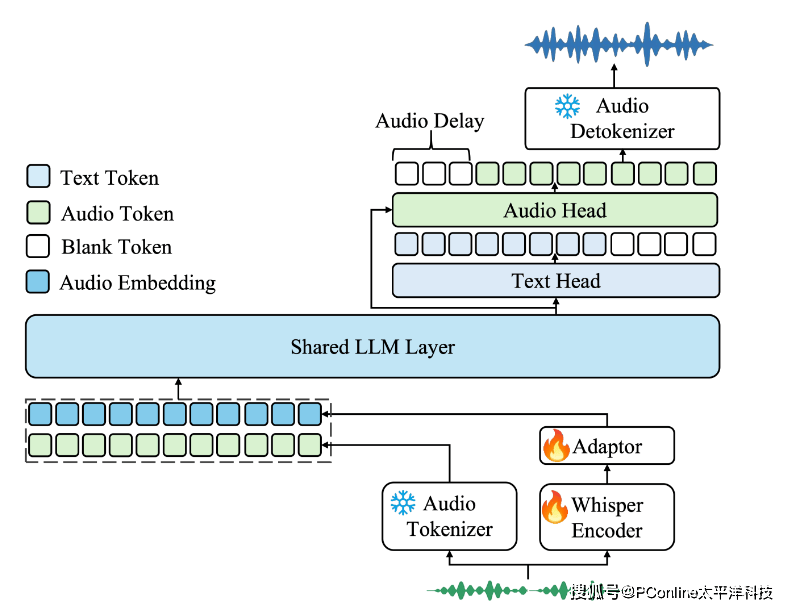
创新集成式架构,三大核心组件
为了攻克音频处理中的语义表征与模态转换难题,Kimi 团队创新性提出由三大核心组件组成的一体化架构。
音频分词器(Audio Tokenizer):采用矢量量化(VQ)技术将音频信号转化为12.5Hz 离散语义 Token,同步提取连续声学特征,在保留语音细节(如语调、重音)的同时实现高效语义压缩,为后续建模提供兼具粒度与精度的基础输入。
音频大模型(Audio LLM):基于共享 Transformer 架构构建多模态处理核心,通过文本 - 音频交错预训练策略,实现跨模态知识对齐。模型支持音频输入生成文本(如 ASR)、文本输入生成音频(如 TTS),并在对话场景中动态切换模态处理路径,单模型支持超 20 种音频任务无缝切换。
音频去分词器(Audio Detokenizer):引入流匹配(Flow Matching)技术优化音频生成,相比传统 WaveNet 方案,生成语音的自然度 MOS 评分提升1.2分,支持多音色、多语言合成,单设备实时生成效率提升50%。

1300万小时音频+独特训练法
对于大模型而言,训练的数量和质量也是非常重要的。Kimi-Audio在超过1300万小时的多样化音频数据上进行训练,包括语音、音乐和环境声音等,并且还使用创新的训练方法提升效率。
超大规模预训练:基于1300万小时多维度音频数据(含10万小时音乐、200万小时多语种对话、500万小时环境声)构建预训练语料库,通过“语音增强 - 说话人分离 - 跨模态对齐”流水线清洗数据,解决传统音频数据标注成本高、噪声干扰大的痛点。
多任务协同微调:在30万小时监督数据上进行定向优化,针对 ASR 任务设计 200 条指令模板(如 “识别会议录音中的技术术语”),其他任务配置 30 条通用指令,通过随机指令注入增强模型泛化性。训练过程采用 AdamW 优化器与余弦衰减策略,关键任务收敛速度提升 40%。
端到端闭环验证:自研音频 LLM 评估工具包,覆盖 ASR、AQA(音频问答)、SER(语音情感识别)等 8 大任务类型,支持多模型公平对比。可视化雷达图显示,Kimi-Audio在13项基准测试中综合得分覆盖所有竞品外沿,成为首个无明显短板的“全能型”音频模型。
声音是AI与物理世界的连接
Kimi-Audio 就像给 AI装了一对“聪明耳朵”和一张“灵活嘴巴”,让机器不再是只会机械回应的呆子,而是能真正“听懂你、回应你、甚至帮你干活”的伙伴。未来你家的智能音箱、车载语音助手、甚至耳机,可能都藏着这个“中国造”的声音大脑。
而且,它现在就开源了,所有人都能上车玩起来!





